

Limiter l’utilisation de l’API en fonction d’une règle avancée de limitation du débit n’est pas si facile. Pour y parvenir avec l’API NLP Cloud, nous utilisons une combinaison de Traefik (comme proxy inverse) et de mise en cache locale dans un script Go. Si cela est fait correctement, vous pouvez améliorer considérablement les performances de votre limitation de débit et étrangler correctement les demandes d’API sans sacrifier la vitesse des demandes.
Dans cet exemple, nous montrons comment déléguer la limitation de débit de chaque requête API à un microservice dédié grâce à Traefik et Docker. Ensuite, dans ce microservice dédié, nous allons compter le nombre de requêtes récemment effectuées afin d’autoriser ou non la nouvelle requête.
Traefik comme reverse proxy
Pour mettre en place une passerelle API, Traefik et Docker sont une très bonne combinaison.
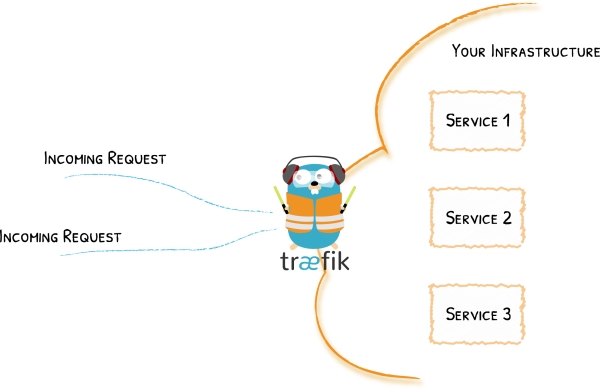
L’idée est que toutes vos demandes d’API soient d’abord acheminées vers un conteneur Docker contenant une instance Traefik. Cette instance Traefik agit comme un proxy inverse et effectue donc des opérations telles que l’authentification, le filtrage, la réessai, … pour finalement acheminer la demande de l’utilisateur vers le bon conteneur.
Par exemple, si vous faites une demande de résumé de texte sur NLP Cloud, vous passerez d’abord par la passerelle API qui se chargera d’authentifier votre demande et, si elle est authentifiée avec succès, votre demande sera acheminée vers un modèle d’apprentissage automatique de résumé de texte contenu dans un conteneur Docker dédié hébergé sur un serveur spécifique.
Traefik et Docker sont tous deux faciles à utiliser, et ils rendent votre programme assez facile à maintenir.
Pourquoi utiliser Go?
Un script de limitation de débit devra nécessairement gérer un énorme volume de requêtes simultanées.
Go est un bon candidat pour ce type d’application car il traite les demandes très rapidement, et sans consommer trop de CPU et de RAM.
Traefik et Docker ont tous deux été écrits en Go, ce qui ne doit pas être une coïncidence…
Une mise en œuvre naïve consisterait à utiliser la base de données pour stocker l’utilisation de l’API, compter les demandes passées des utilisateurs et limiter les demandes en fonction de cela. Cela soulèvera rapidement des problèmes de performance, car le fait d’effectuer une requête à la base de données chaque fois que vous voulez vérifier une demande surchargera la base de données et créera des tonnes d’accès inutiles au réseau. La meilleure solution est de gérer cela localement en mémoire. Le revers de la médaille, bien sûr, est que les compteurs en mémoire ne sont pas persistants : si vous redémarrez votre application de limitation de débit, vous perdrez tous vos compteurs en cours. En théorie, cela ne devrait pas être un gros problème pour une application de limitation de débit.
Délégation du rate limiting de l’API à un microservice dédié grâce à Traefik et Docker
Traefik possède de nombreuses fonctionnalités intéressantes. L’une d’entre elles est la possibilité de transmettre l’authentification à un service dédié.
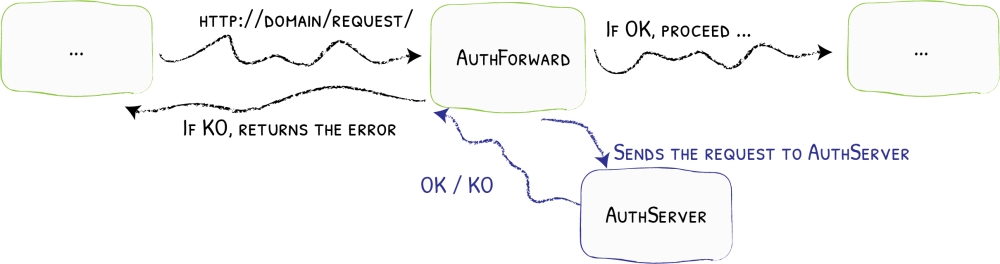
Fondamentalement, chaque demande d’API entrante sera d’abord transmise à un service dédié. Si ce service renvoie un code 2XX, alors la demande est acheminée vers le service approprié, sinon elle est rejetée.
Dans l’exemple suivant, nous allons utiliser un fichier Docker Compose pour un cluster Docker Swarm. Si vous utilisez un autre orchestrateur de conteneurs comme Kubernetes, Traefik fonctionnera très bien aussi.
Tout d’abord, créez un fichier Docker Compose pour votre endpoint API et activez Traefik :
version: "3.8"
services:
traefik:
image: "traefik"
command:
- --providers.docker.swarmmode
api_endpoint:
image: path_to_api_endpoint_image
deploy:
labels:
- traefik.http.routers.api_endpoint.entrypoints=http
- traefik.http.services.api_endpoint.loadbalancer.server.port=80
- traefik.http.routers.api_endpoint.rule=Host(`example.com`) && PathPrefix(`/api-endpoint`)
Ensuite, ajoutez un nouveau service dédié à la limitation de débit et demandez à Traefik de lui transmettre toutes les requêtes (nous coderons ce service Go rate limiting un peu plus tard) :
version: "3.8"
services:
traefik:
image: traefik
command:
- --providers.docker.swarmmode
api_endpoint:
image: path_to_your_api_endpoint_image
deploy:
labels:
- traefik.http.routers.api_endpoint.entrypoints=http
- traefik.http.services.api_endpoint.loadbalancer.server.port=80
- traefik.http.routers.api_endpoint.rule=Host(`example.com`) && PathPrefix(`/api-endpoint`)
- traefik.http.middlewares.forward_auth_api_endpoint.forwardauth.address=http://rate_limiting:8080
- traefik.http.routers.api_endpoint.middlewares=forward_auth_api_endpoint
rate_limiting:
image: path_to_your_rate_limiting_image
deploy:
labels:
- traefik.http.routers.rate_limiting.entrypoints=http
- traefik.http.services.rate_limiting.loadbalancer.server.port=8080
Nous avons maintenant une configuration complète Docker Swarm + Traefik qui transmet d’abord les demandes à un service de limitation de débit avant de router éventuellement la demande vers le point final de l’API. Vous pouvez mettre ce qui précède dans un fichier production.yml et démarrer l’application avec la commande suivante :
docker stack deploy --with-registry-auth -c production.yml application_name
Notez que seuls les en-têtes des demandes sont transférés, et non le contenu des demandes. Ceci est pour des raisons de performance. Donc, si vous voulez authentifier une demande sur la base du corps de cette demande, vous devrez trouver une autre stratégie.
Gérer le rate limiting avec Go et la mise en cache
Les configurations de Traefik et de Docker sont prêtes. Nous devons maintenant coder le microservice Go qui se chargera de limiter le débit des demandes : les utilisateurs n’ont droit qu’à 10 demandes par minute. Au-delà de 10 demandes par minute, chaque demande sera rejetée avec un code HTTP 429.
package main
import (
"fmt"
"time"
"log"
"net/http"
"github.com/gorilla/mux"
"github.com/patrickmn/go-cache"
)
var c *cache.Cache
// updateUsage increments the API calls in local cache.
func updateUsage(token) {
// We first try to increment the counter for this user.
// If there is no existing counter, an error is returned, and in that
// case we create a new counter with a 3 minute expiry (we don't want
// old counters to stay in memory forever).
_, err := c.IncrementInt(fmt.Sprintf("%v/%v", token, time.Now().Minute()), 1)
if err != nil {
c.Set(fmt.Sprintf("%v/%v", token, time.Now().Minute()), 1, 3*time.Minute)
}
}
func RateLimitingHandler(w http.ResponseWriter, r *http.Request) {
// Retrieve user API token from request headers.
// Not implemented here for the sake of simplicity.
apiToken := retrieveAPIToken(r)
var count int
if x, found := c.Get(fmt.Sprintf("%v/%v", apiToken, time.Now().Minute())); found {
count = x.(int)
}
if count >= 10 {
w.WriteHeader(http.StatusTooManyRequests)
return
}
updateUsage(apiToken)
w.WriteHeader(http.StatusOK)
}
func main() {
r := mux.NewRouter()
r.HandleFunc("/", RateLimitingHandler)
log.Println("API is ready and listening on 8080.")
log.Fatal(http.ListenAndServe(":8080", r))
}
Comme vous pouvez le voir, nous utilisons le Gorilla toolkit afin de créer une petite API, écoutant sur le port 8080, qui recevra la requête transmise par Traefik.
Une fois la requête reçue, nous extrayons le jeton API de l’utilisateur de la requête (non implémenté ici pour des raisons de simplicité), et vérifions le nombre de requêtes effectuées par l’utilisateur associé à ce jeton API au cours de la dernière minute.
Le compteur de requêtes est stocké en mémoire grâce à la bibliothèque go-cache. Go-cache est une bibliothèque de mise en cache minimaliste pour Go qui est très similaire à Redis. Elle gère automatiquement les éléments importants comme l’expiration du cache. Le stockage des compteurs d’API en mémoire est crucial car c’est la solution la plus rapide, et nous voulons que ce code soit aussi rapide que possible afin de ne pas trop ralentir les demandes d’API.
Si l’utilisateur a fait plus de 10 demandes pendant la minute en cours, la demande est rejetée avec un code d’erreur HTTP 429. Traefik verra que cette erreur 429 n’est pas un code 2XX, donc il ne permettra pas à la requête de l’utilisateur d’atteindre le endpoint API, et il propagera l’erreur 429 à l’utilisateur.
Si la demande n’est pas limitée en débit, nous incrémentons automatiquement le compteur pour cet utilisateur.
Je vous recommande de déployer cette application Go dans un simple conteneur “scratch” (FROM scratch) : c’est la manière la plus légère de déployer des binaires Go avec Docker.
Conclusion
Comme vous pouvez le constater, la mise en œuvre d’une passerelle de limitation de débit pour votre API n’est pas si difficile, grâce à Traefik, Docker et Go.
Bien sûr, la limitation du débit en fonction du nombre de demandes par minute n’est qu’une première étape. Vous pourriez vouloir faire des choses plus avancées comme :
- Limitation du débit par minute, par heure, par jour et par mois.
- Limitation du débit par point de terminaison de l’API
- Avoir une limite de débit variable par utilisateur en fonction du plan auquel il a souscrit.
- Vérifier la concurrence
Il y a tellement de choses intéressantes que nous ne pouvons pas mentionner dans cet article !
Si vous avez des questions, n’hésitez pas à m’en faire part.





{kind=link}