
{kind=link}
Le suivi de l’utilisation des API peut être un véritable défi technique en raison de la vitesse et du volume élevés des demandes. Pourtant, il est crucial de disposer d’analyses précises pour votre API, surtout si vous vous en servez pour facturer vos clients. Il est possible d’être à la fois rapide et précis avec une base de données de séries temporelles appelée TimescaleDB. Il s’agit en fait de la solution que nous avons mise en œuvre derrière NLP Cloud.
Qu’est-ce que l’analyse des API et pourquoi est-ce difficile ?
L’analyse des API consiste à récupérer diverses mesures liées à l’utilisation de votre API.
Par exemple, derrière l’API NLP Cloud, nous souhaitons connaître les éléments suivants :
- Combien de demandes ont été faites au cours de la dernière minute, de la dernière heure, du dernier jour, du dernier mois et de la dernière année ?
- Combien de requêtes ont été faites par point de terminaison de l’API et par utilisateur ?
- Combien de mots ont été générés par nos modèles NLP de génération de texte (comme GPT-J) ?
- Combien de caractères ont été utilisés par notre module NLP multilingue ?
Toutes ces mesures sont importantes pour mieux comprendre comment notre API est utilisée par nos clients. Sans ces données, nous sommes incapables de savoir quels modèles NLP sont les plus utilisés, qui sont nos clients les plus importants, etc.
Mais plus important encore, certaines de ces mesures sont utilisées pour la facturation ! Par exemple, les clients qui ont souscrit à un plan “pay-as-you-go” sont facturés en fonction du nombre de mots qu’ils ont générés avec notre API.
Un très grand volume de données passe par notre passerelle API, ce qui constitue un défi en termes de performances. Il est très facile de ralentir l’API ou de perdre des données.
Il est donc essentiel qu’un tel système d’analyse des API soit à la fois rapide et fiable.
TimescaleDB à la rescousse
TimescaleDB est une base de données PostgreSQL optimisée pour les séries chronologiques.

Fondamentalement, Timescale est optimisé pour un volume élevé d’écritures atomiques. Il est parfait pour un cas d’utilisation où vous écrivez des tonnes de données sur une base très régulière, mais ne modifiez presque jamais ces données, et ne les lisez qu’occasionnellement.
Timescale propose des outils intéressants qui facilitent la création de séries chronologiques. Par exemple, il existe des “agrégats continus”. Ces agrégats sont un moyen de réduire automatiquement l’échantillonnage de vos données sur une base régulière. L’échantillonnage réduit signifie que vous supprimez les anciennes données après un certain temps et que vous ne conservez que certains agrégats de ces données (basés sur des sommes, des comptages, des moyennes, etc.) C’est crucial pour deux raisons :
- Les séries chronologiques peuvent croître très rapidement, c’est donc un très bon moyen d’économiser de l’espace disque.
- La lecture d’une table remplie de données peut être terriblement lente. Il est beaucoup plus facile de lire les données d’une table agrégée qui contient moins de données.
Contrairement à d’autres solutions comme InfluxDB, TimescaleDB est une solution purement SQL, la courbe d’apprentissage est donc assez faible et l’intégration sera beaucoup plus facile. Par exemple, chez NLP Cloud, nous interagissons avec TimescaleDB dans des applications Python et Go et nous pouvons utiliser nos bibliothèques PostgreSQL habituelles.
Installation
Vous pouvez installer TimescaleDB en tant que package système, mais il est plus simple de l’installer en tant que conteneur Docker.
Commencez par télécharger l’image Docker :
docker pull timescale/timescaledb:latest-pg14
Ensuite, démarrez votre conteneur et passez un mot de passe pour votre DB :
docker run -d --name timescaledb -p 5432:5432 -e POSTGRES_PASSWORD=password timescale/timescaledb:latest-pg14
Structure des données dans TimescaleDB
Dans cet exemple, nous voulons stocker les demandes d’API. Nous voulons que chaque demande contienne les éléments suivants :
- L’heure de la demande
- L’identifiant de l’utilisateur qui a fait la demande
- Le point de terminaison de l’API utilisé pendant la demande
La première fois que vous lancez TimescaleDB, vous devez créer plusieurs choses.
Tout d’abord, lancez l’extension TimescaleDB.
CREATE EXTENSION IF NOT EXISTS timescaledb;
Créez la table qui stockera les demandes d’API, comme nous le ferions dans toute base de données PostgreSQL :
CREATE TABLE IF NOT EXISTS api_calls (
time TIMESTAMPTZ NOT NULL,
user_id TEXT NOT NULL,
endpoint TEXT NOT NULL
);
Nous en faisons ensuite un “hypertable” :
SELECT create_hypertable('api_calls', 'time', if_not_exists => TRUE);
Les tables horizontales sont le cœur de TimescaleDB. Elles ajoutent automatiquement de nombreux éléments intelligents afin de gérer efficacement vos données.
Nous allons maintenant créer une vue spécifique à partir de votre table api_calls appelée api_calls_per_hour. C’est une vue qui stockera les données agrégées provenant de api_calls. Toutes les heures, le nombre de requêtes API dans api_calls sera compté et placé dans api_calls_per_hour. La vue sera beaucoup plus rapide à interroger puisqu’elle contient beaucoup moins de données que la table initiale api_calls.
CREATE MATERIALIZED VIEW IF NOT EXISTS api_calls_per_hour
WITH (timescaledb.continuous) AS
SELECT time_bucket('1 hour', time) as bucket, user_id, endpoint,
COUNT(time)
FROM api_calls
GROUP BY bucket, user_id, endpoint;
Enfin, nous créons une politique d’agrégation continue et une politique de rétention. Les deux seront gérées par des workers en arrière-plan. La plupart du temps, tout fonctionne bien, mais si vous commencez à avoir beaucoup de politiques, vous risquez de manquer de workers en arrière-plan et vous verrez des messages d’erreur dans vos journaux. Dans ce cas, l’astuce est d’augmenter votre nombre de workers en arrière-plan dans /var/lib/postgresql/data/postgresql.conf.
La politique d’agrégation continue se chargera d’échantillonner régulièrement les données de api_calls et de les mettre dans api_calls_per_hour. La politique de rétention se chargera de supprimer les anciennes données de api_calls afin que vous ne manquiez jamais d’espace disque :
SELECT add_continuous_aggregate_policy('api_calls_per_hour',
start_offset => INTERVAL '1 day',
end_offset => INTERVAL '1 hour',
schedule_interval => INTERVAL '1 minute',
if_not_exists => TRUE);
SELECT add_retention_policy('api_calls', INTERVAL '90 days', if_not_exists => TRUE);
Comme vous pouvez le voir, ce n’était pas trop complexe.
Insertion de données
Dans votre application, vous pouvez maintenant vous connecter à votre base de données Timescale et insérer des requêtes.
Par exemple, voici comment vous pourriez le faire en Python :
import psycopg2
conn = psycopg2.connect(
"host=timescaledb dbname={} user={} password={}".format("name", "user", "password"))
cur = conn.cursor()
cur.execute("INSERT INTO api_calls (time, user_id, endpoint) VALUES (%s, %s, %s)",
(datetime.now(), "1584586", "/v1/gpu/bart-large-cnn/summarization"))
conn.commit()
cur.close()
conn.close()
Et maintenant en Go :
import (
"github.com/jackc/pgx/v4"
"github.com/jackc/pgx/v4/pgxpool"
)
func main(){
timescaledbURL := fmt.Sprintf("postgres://%s:%s@timescaledb:5432/%s", "user", "password", "name")
timescaledbDatabase, err := pgxpool.Connect(context.Background(), timescaledbURL)
if err != nil {
log.Fatalf("Cannot connect to TimescaleDB database: %v. Stopping here.", err)
}
query := `INSERT into api_calls (time, user_id, endpoint) VALUES ($1, $2, $3)`
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
_, err := timescaledbDatabase.Exec(ctx, query, time.Now(), "1584586", "/v1/gpu/bart-large-cnn/summarization")
if err != nil {
log.Printf("Cannot insert metric in TimescaleDB: %v", err)
}
}
Point important : vous ne voulez probablement pas ralentir les demandes de l’API utilisateur à cause d’un traitement potentiellement lent du côté de TimescaleDB. La solution consiste à insérer vos données de manière asynchrone, de sorte que la réponse de l’API utilisateur soit renvoyée même si les données ne sont pas encore insérées dans votre base de données. Mais cela dépasse le cadre de cet article.
Afin d’améliorer le débit, vous pouvez également insérer plusieurs requêtes API en une seule fois. L’idée est que vous devez d’abord mettre en cache certaines demandes en mémoire, puis en enregistrer plusieurs dans la base de données en une seule fois après un certain temps.
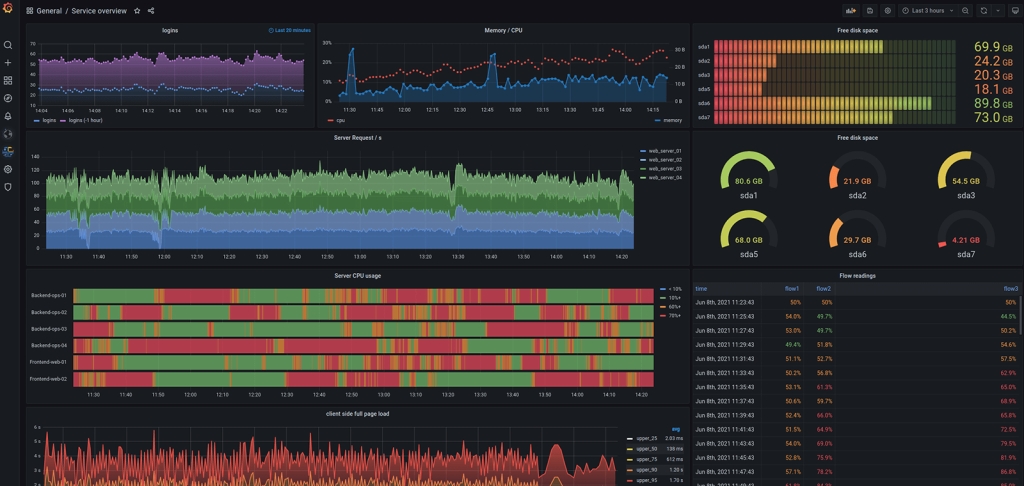
Visualisation des données
Il existe de nombreux outils de visualisation des données. J’aime Grafana parce qu’il est facile de le brancher sur TimescaleDB et que les possibilités de graphiques sont innombrables.
Voici un bon tutoriel sur la façon de configurer TimescaleDB avec Grafana : voir ici.
Conclusion
TimescaleDB est un outil puissant pour les séries chronologiques, et c’est une excellente solution si vous voulez analyser correctement l’utilisation de votre API.
Comme vous pouvez le constater, la configuration et l’utilisation de TimescaleDB sont assez simples. Attention toutefois : TimescaleDB peut rapidement utiliser beaucoup de RAM, alors assurez-vous de garder cela à l’esprit avant de provisionner votre instance de serveur.
Si vous avez des questions, n’hésitez pas à les poser !