
{kind=link}
J’utilise le programme Torrench depuis un moment maintenant et je trouve que c’est un super outil en Python pour facilement rechercher des torrents en console (CLI). Je me suis dit que je pourrais essayer de développer un outil similaire en Go (Golang) puisque ce serait une bonne opportunité pour moi d’apprendre de nouvelles choses et que je pourrais introduire de la concurrence dans ce programme, ce qui augmenterait sensiblement les performances (Torrench est lent à cet égard).
Laissez-moi vous parler des fonctionnalités de ce nouveau programme ici, vous montrer comment ils gère la concurrence, et enfin vous expliquer comment j’ai organisé cette bibliothèque Go en vue d’une réutilisation par des tiers.
Fonctionnalités de Torrengo
Torrengo est un programme en ligne de commande (CLI) qui recherche les torrents (fichiers torrents et liens magnet) de façon concurrente depuis différents sites web. Rechercher des torrents a toujours été une catastrophe pour moi puisque ça signifiait à chaque fois lancer la même recherche sur de nombreux sites, faire face à des sites qui fonctionnent mal, et se retrouver inondé de pub scandaleuses… ce petit outil est là pour tout résoudre. Voici un aperçu des fonctionnalités clés de Torrengo au moment où j’écris ces lignes.
Un programme CLI simple
J’ai réalisé que je n’avais pas beaucoup d’expérience concernant l’écriture d’outils en ligne de commande, je me suis donc dit que ce petit projet serait une bonne façon d’améliorer mes compétences en la matière.
Les programmes CLI dédiés à des cas d’usage très spécifiques comme celui-là et avec très peu d’interaction utilisateur peuvent s’avérer être beaucoup plus clairs et légers qu’un GUI. Ils peuvent aussi facilement se brancher à d’autres programmes.
Vous pouvez lancer une nouvelle recherche de cette façon :
./torrengo Alexandre Dumas
Cela retournera tous les résultats trouvés sur tous les sites, le tout classé par nombre de seeders, et c’est à vous de décider lequel vous souhaitez alors télécharger :
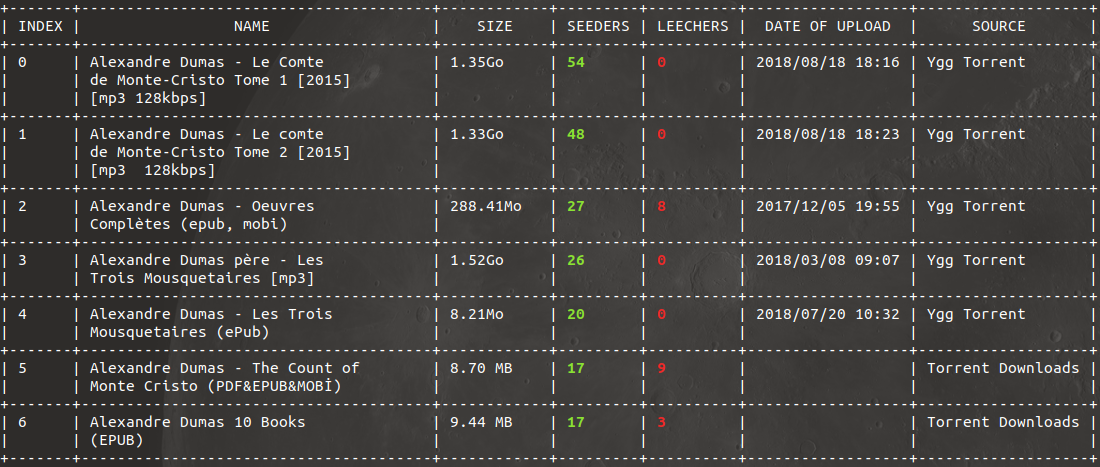
Vous pouvez aussi décider d’effectuer une recherche sur certains sites uniquement (disons The Pirate Bay et Archive.org) :
./torrengo -s tpb,arc Alexandre Dumas
Si vous souhaitez voir plus de logs (mode verbeux), ajoutez simplement le flag -v.
Rapide
Go étant un langage très performant et avec lequel il est facile de coder des programmes concurrents, Torrengo récupère la liste de torrents très rapidement. Au lieu de chercher sur chaque site un par un de façon séquentielle, il cherche sur tous en parallèle.
Torrengo est aussi rapide que la plus lente des réponse HTTP. Parfois la réponse HTTP la plus lente peut prendre plus de temps que vous ne l’auriez souhaité (par exemple Archive.org est assez lent depuis la France au moment où j’écris ces lignes). Dans ce cas, comme Torrengo supporte les timeouts, il vous suffit de déclarer un timeout comme suit :
./torrengo -t 2000 Alexandre Dumas
La commande ci-dessus stoppe toutes les requêtes HTTP qui prennent plus de 2 secondes et retourne les autres résultats trouvés.
Utilise les proxies pour The Pirate Bay
Les urls pour The Pirate Bay changent assez régulièrement et la plupart d’entre elles fonctionnent de façon erratique. Pour contourner ce problème, le programme lance une recherche concurrente sur toutes les urls The Pirate Bay trouvées sur un site listant tous les proxies (proxybay.bz à l’heure où j’écris ces lignes) et récupère les torrents depuis la réponse la plus rapide.
Le HTML de l’url retournée est aussi contrôlé en détails car certains proxies retournent parfois une page sans aucune erreur HTTP mais la page ne contient en réalité aucun résultat…
Contourner la protection Cloudflare sur Torrent Downloads
Télécharger des fichiers torrent depuis le site de Torrent Downloads est difficile car ce dernier a une protection Cloudflare qui consiste en un challenge Javascript auquel il faut répondre. Torrengo tente de contourner cette protection en résolvant ce challenge Javascript, chose qui fonctionne 90% du temps au moment à l’heure où j’écris cet article.
Authentification
Certains sites de torrents comme Ygg Torrent (anciennement t411) obligent les utilisateurs à s’authentifier afin de télécharger le fichier torrent. Torrengo gère cela en demandant ses identifiants à l’utilisateur (mais bien entendu il vous faut un compte en premier lieu).
Avertissement : ne faites jamais confiance aux programmes qui demandent vos identifiants sans avoir mis votre nez dans le code source au préalable.
Ouvrir dans le client torrent
Au lieu de copier coller les liens magnet trouvés par Torrengo dans votre client torrent ou de chercher le fichier torrent téléchargé pour l’ouvrir, vous pouvez simplement dire au programme d’ouvrir le torrent dans client local directement. Seul Deluge est supporté pour le moment.
Concurrence
Grâce à la simplicité de Go, la façon dont la concurrence est gérée dans ce programme n’est pas difficile à comprendre. C’est particulièrement vrai ici car la concurrence se prête particulièrement bien aux programmes faisant beaucoup d’appels réseau comme celui-ci. En gros la goroutine “main” crée une nouvelle goroutine pour chaque scraper et récupère les résultats dans des structs via des channels dédiés. tpb est un cas particulier puisque la bibliothèque crée à son tour n goroutines, n étant les nombre d’urls trouvées sur le site de proxies.
J’en profite pour dire que j’ai appris 2 petites choses intéressantes en termes de bonnes pratiques concernant les channels :
- chaque goroutine de recherche retourne à la fois une erreur et un résultat. J’ai décidé de créer un channel dédié pour le résultat (une struct) et un autre pour l’erreur, mais je sais que certains préfèrent retourner les deux au sein d’une même struct. Ça dépend de vous, les deux sont ok.
- les goroutines créées par
tpbn’ont pas besoin de retourner une erreur mais simplement de signaler qu’elles se sont terminées. C’est ce que l’on appelle un “événement”. J’ai modélisé cela via l’envoi d’une struct vide (struct{}{}) sur la channel, ce qui semble le plus pertinent du point de vue de l’utilisation mémoire puisqu’une struct vide ne pèse rien. La seconde option et de passer un booléenok, ce qui fonctionne parfaitement aussi.
Structure de la bibliothèque
Cette bibliothèque est composée de plusieurs sous bibliothèques : une pour chaque scraper. Le but est que chaque bibliothèque de scraping soit le moins couplée possible au programme général Torrengo afin de pouvoir être réutilisée dans des projets tiers. Chaque scraper a sa propre documentation.
Voici la structure actuelle du projet :
torrengo
├── arc
│ ├── download.go
│ ├── README.md
│ ├── search.go
├── core
│ ├── core.go
├── otts
│ ├── download.go
│ ├── README.md
│ ├── search.go
├── td
│ ├── download.go
│ ├── README.md
│ ├── search.go
├── tpb
│ ├── proxy.go
│ ├── README.md
│ ├── search.go
├── ygg
│ ├── download.go
│ ├── login.go
│ ├── README.md
│ ├── search.go
├── README.md
├── torrengo.go
Je vais vous donner quelques détails sur la façon dont j’ai organisé ce projet Go (j’aurais beaucoup aimé recevoir ce genre de conseils sur les bonnes pratiques à suivre concernant la structuration des projets Go).
Un package Go par répertoire
Comme je l’ai dit plus haut, j’ai créé une bibliothèque pour chaque scraper. Tous les fichiers contenus dans le même répertoire appartiennent au même package Go. Dans le dessin ci-dessus il y a 5 bibliothèques de scraping :
- arc (Archive.org)
- otts (1337x)
- td (Torrent Downloads)
- tpb (The Pirate Bay)
- ygg (Ygg Torrent)
Chaque bibliothèque peut-être utilisée dans un autre projet go en l’important comme suit (par exemple pour Archive.org) :
import "github.com/juliensalinas/torrengo/arc"
La bibliothèque core contient les choses communes à toutes les bibliothèques de scraping, et sera ainsi importée par chacune d’elles.
Chaque bibliothèque de scraping a sa propre documentation (README) afin d’être parfaitement découplée.
Plusieurs fichiers par répertoire
Chaque répertoire contient plusieurs fichiers pour faciliter la lisibilité. Avec Go, vous pouvez créer autant de fichiers que vous le souhaitez pour le même package tant que vous mentionnez le nom du package en haut de chaque fichier. Par exemple ici chaque fichier contenu dans le dossier arc possède la ligne suivante tout en haut :
package arc
Par exemple dans arc j’ai organisé les choses de façon à ce que chaque struct, méthode, fonction, variable, liées au téléchargement du fichier torrent final aille dans le fichier download.go.
Commande
Certains développeurs Go mettent tout ce qui est lié aux commandes, c’est-à-dire les parties du programme dédiées à l’interaction avec l’utilisateur, dans un répertoire dédié cmd.
Ici, j’ai préféré mettre le tout dans un unique fichier torrengo.go à la racine du projet, ce qui me semblait plus approprié pour un petit programme comme celui-ci.
Conclusion
J’espère que vous aimerez Torrengo et j’adorerais recevoir des feed-back à ce sujet ! Les feed-backs peuvent concerner les fonctionnalités de Torrengo bien entendu, mais si vous êtes un développeur Go et que vous pensez que certaines parties du code peuvent être améliorées j’aimerais beaucoup entendre vos avis aussi.
Je prévois d’écrire d’autres articles autour de ce que j’ai appris en écrivant ce programme !