
I’ve used the Torrench program for quite a while as this is a great Python tool for easy torrent searching in console (CLI). I figured I could try to develop a similar tool in Go (Golang) as it would be a good opportunity for me to learn new stuffs plus I could make this program concurrent and thus dramatically improve speed (Torrench is a bit slow in this regards).
Let me tell you about this new program’s features here, show you how I handled concurrency in it, and then tell you how I organized this Go library for easy reuse by third-parties.
Torrengo Features
Torrengo is a command line (CLI) program that concurrently searches torrents (torrent files and magnet links) from various torrent websites. Looking for torrents has always been a nightmare to me as it means launching the same search on multiple websites, facing broken websites that are not responding, and being flooded by awful ads… so this little tool is here to solve these problems. Here is an insight of the core features of Torrengo as of this writing.
Simple CLI Program
I realized I did not have much experience writing CLI tools so I figured this little project would be a good way to improve my skills in writing command line programs in Go.
CLI programs for very specific use cases like this one and with very few user interactions needed can prove to be much clearer and lighter than a GUI. They can also easily be plugged to other programs.
You can launch a new search like this:
./torrengo Alexandre Dumas
It will return all results found on all websites sorted by seeders, and it’s up to you to decide which one to download then:
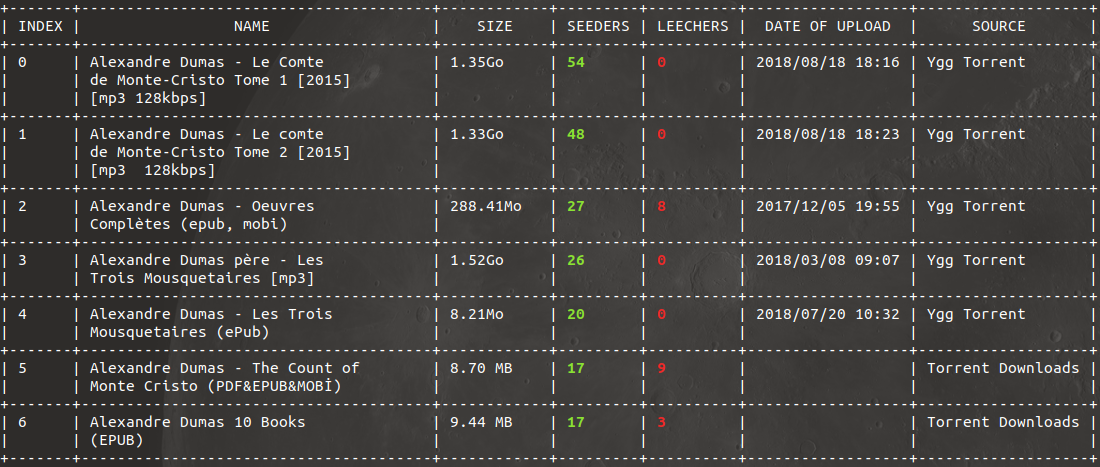
You can also decide to search only specific websites (let’s say The Pirate Bay and Archive.org):
./torrengo -s tpb,arc Alexandre Dumas
If you want to see more logs (verbose mode), just add the -v flag.
Fast
Thanks to Go being a very efficient language and easy to code concurrent programs with, Torrengo is scraping results very fast. Instead of fetching every website sequentially one by one, it fetches everything in parallel.
Torrengo is as fast as the slowest HTTP response then. Sometimes the slowest HTTP response can take more time than you want (for example Archive.org is pretty slow from France as of this writing). In that case, as Torrengo supports timeouts just set a timeout like this:
./torrengo -t 2000 Alexandre Dumas
The above stops every HTTP requests that take more than 2 seconds and returns the other results found.
Use The Pirate Bay Proxies
The Pirate Bay urls are changing quite often and most of them work erratically. To tackle this, the program concurrently launches a search on all The Pirate Bay urls found on a proxy list website (proxybay.bz as of this writing) and retrieves torrents from the fastest response.
The returned url’s HTML is also checked in-depth because some proxies sometimes return a page with no HTTP error but the page actually does not contain any result…
Bypass Cloudflare’s Protection on Torrent Downloads
Downloading torrent files from the Torrent Downloads’ website is difficult because the latter implements a Cloudflare protection that consists of a Javascript challenge to answer. Torrengo tries to bypass this protection by answering the Javascript challenge, which is working 90% of the times as of this writing.
Authentication
Some torrent websites like Ygg Torrent (previously t411) need users to be authenticated to download the torrent files. Torrengo handles this by asking you for credentials (but of course you need to have an account in the first place).
Word of caution: never trust programs that ask for your credentials without having a look into the source code first.
Open in Torrent Client
Instead of copy pasting magnet links found by Torrengo to your torrent client or looking for the downloaded torrent file and opening it, you can just say that you want to open torrent in local client right away. Only supported for Deluge as of this writing.
Concurrency
Thanks to Go’s simplicity, the way concurrency is used in this program is not hard to understand. This is especially true here because concurrency is perfect for networking programs like this one. Basically, the main goroutine spawns one new goroutine for each scraper and retrieves results in structs through dedicated channels. tpb is a special case as the library spawns n goroutines, n being the number of urls found on the proxy website.
I take the opportunity to say that I learned 2 interesting little things regarding channels best practices:
- every scraping goroutines return both an error and a result. I decided to create a dedicated channel for the result (a struct) and another one for the error, but I know that some prefer to return both inside a single struct. It’s up to you, both are fine.
- goroutines spawned by
tpbdon’t need to return an error but just say when they are done. This is something call an “event”. I did it by sending an empty struct (struct{}{}) through the channel which seems the best to me from a memory footprint standpoint as an empty struct weighs nothing. Instead you could also pass anokboolean variable which is perfectly fine too.
Library Structure
This lib is made up of multiple sub-libraries: one for each scraper. The goal is that every scraping library is loosely coupled to the Torrengo program so it can be reused easily in other third-party projects. Every scraper has its own documentation.
Here is the current project’s structure:
torrengo
├── arc
│ ├── download.go
│ ├── README.md
│ ├── search.go
├── core
│ ├── core.go
├── otts
│ ├── download.go
│ ├── README.md
│ ├── search.go
├── td
│ ├── download.go
│ ├── README.md
│ ├── search.go
├── tpb
│ ├── proxy.go
│ ├── README.md
│ ├── search.go
├── ygg
│ ├── download.go
│ ├── login.go
│ ├── README.md
│ ├── search.go
├── README.md
├── torrengo.go
Let me give you more details about how I organized this Go project (I wish I had more advice like this regarding Go project structures’ best practice before).
One Go Package Per Folder
Like I said earlier, I created one lib for each scraper. All files contained in the same folder belong to the same Go package. In the chart above there are 5 scraping libs:
- arc (Archive.org)
- otts (1337x)
- td (Torrent Downloads)
- tpb (The Pirate Bay)
- ygg (Ygg Torrent)
Each lib can be used in another Go project by importing it like this (example for Archive.org):
import "github.com/juliensalinas/torrengo/arc"
The core lib contains things common to all scraping libs and thus will be imported by all of them.
Each scraping lib has its own documentation (README) in order for it to be really decoupled.
Multiple Files Per Folder
Every folder contain multiple files for easier readability. In Go, you can create as many files as you want for the same package as long as you mention the name of the package at the top of the file. For example here every files contained in the arc folder have the following line at the top:
package arc
For example in arc I organized things so that every structs, methods, functions, variables, related to the download of the final torrent file go into the download.go file.
Command
Some Go developers put everything related to commands, that’s to say the part of your program dedicated to interacting with the user, in a special cmd folder.
Here I preferred to put this in a torrengo.go file at the root of the project which seemed more appropriate for a small program like this.
Conclusion
I hope you’ll like Torrengo and I would love to receive feed-backs about it! Feed-backs can be about the features of Torrengo of course, but if you’re a Go programmer and you think some parts of my code can be improved I’d love to hear your ideas as well.
I am planning to write more articles about what I learned when writing this program!