

Limitar el uso de la API basándose en una regla avanzada de limitación de velocidad no es tan fácil. Para lograr esto detrás de la API NLP Cloud, estamos utilizando una combinación de Traefik (como proxy inverso) y el almacenamiento en caché local dentro de un script Go. Cuando se hace correctamente, se puede mejorar considerablemente el rendimiento de la limitación de la tasa y acelerar adecuadamente las solicitudes de la API sin sacrificar la velocidad de las solicitudes.
En este ejemplo mostramos cómo delegar la limitación de velocidad de cada petición de la API a un microservicio dedicado gracias a Traefik y Docker. Luego, en este microservicio dedicado, contaremos el número de peticiones realizadas recientemente para autorizar o no la nueva petición.
Traefik como reverse proxy
Para montar una pasarela API, Traefik y Docker son una muy buena combinación.
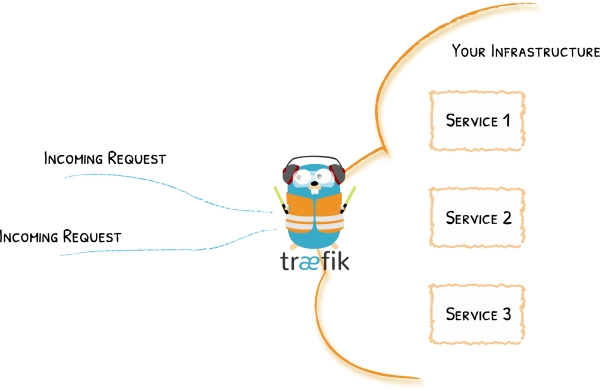
La idea es que todas las solicitudes de la API se dirijan primero a un contenedor Docker que contenga una instancia de Traefik. Esta instancia de Traefik actúa como un proxy inverso, por lo que hará cosas como la autenticación, el filtrado, el reintento, … y finalmente el enrutamiento de la solicitud del usuario al contenedor correcto.
Por ejemplo, si estás haciendo una solicitud de resumen de texto en NLP Cloud, primero pasarás por la puerta de enlace de la API que se encargará de autenticar tu solicitud y, si se autentica con éxito, tu solicitud se dirigirá a un modelo de aprendizaje automático de resumen de texto contenido en un contenedor Docker dedicado alojado en un servidor específico.
Tanto Traefik como Docker son fáciles de usar, y hacen que su programa sea bastante fácil de mantener.
¿Por qué usar Go?
Un script de limitación de velocidad tendrá que manejar necesariamente un gran volumen de peticiones concurrentes.
Go es un buen candidato para este tipo de aplicaciones, ya que procesa sus peticiones muy rápidamente, y sin consumir demasiada CPU y RAM.
Tanto Traefik como Docker fueron escritos en Go, lo que no debe ser una coincidencia…
Una implementación ingenua sería utilizar la base de datos para almacenar el uso de la API, contar las solicitudes pasadas de los usuarios, y limitar las solicitudes en base a eso. Rápidamente surgirán problemas de rendimiento, ya que hacer una petición a la base de datos cada vez que se quiera comprobar una petición saturará la base de datos y creará toneladas de accesos a la red innecesarios. La mejor solución es gestionar esto localmente en la memoria. La otra cara de la moneda, por supuesto, es que los contadores en memoria no son persistentes: si reinicias tu aplicación de limitación de velocidad, perderás todos tus contadores en curso. En teoría, no debería ser un gran problema para una aplicación de limitación de velocidad.
Delegación de la limitación de la tasa de la API a un microservicio dedicado gracias a Traefik y Docker
Traefik tiene muchas características interesantes. Una de ellas es la posibilidad de reenviar la autenticación a un servicio dedicado.
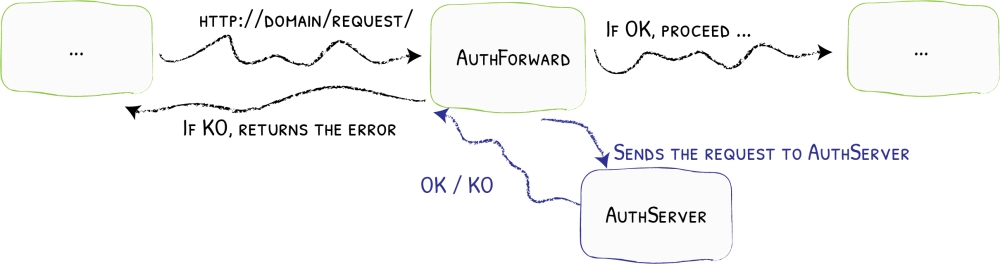
Básicamente, cada solicitud de API entrante se reenvía primero a un servicio dedicado. Si este servicio devuelve un código 2XX, entonces la solicitud se enruta al servicio adecuado, de lo contrario se rechaza.
En el siguiente ejemplo, utilizaremos un archivo Docker Compose para un clúster Docker Swarm. Si estás usando otro orquestador de contenedores como Kubernetes, Traefik también funcionará muy bien.
Primero, crea un archivo Docker Compose para tu punto final de la API y habilita Traefik:
version: "3.8"
services:
traefik:
image: "traefik"
command:
- --providers.docker.swarmmode
api_endpoint:
image: path_to_api_endpoint_image
deploy:
labels:
- traefik.http.routers.api_endpoint.entrypoints=http
- traefik.http.services.api_endpoint.loadbalancer.server.port=80
- traefik.http.routers.api_endpoint.rule=Host(`example.com`) && PathPrefix(`/api-endpoint`)
A continuación, añada un nuevo servicio dedicado a la limitación de velocidad y pida a Traefik que le reenvíe todas las peticiones (codificaremos este servicio de limitación de velocidad Go un poco más tarde):
version: "3.8"
services:
traefik:
image: traefik
command:
- --providers.docker.swarmmode
api_endpoint:
image: path_to_your_api_endpoint_image
deploy:
labels:
- traefik.http.routers.api_endpoint.entrypoints=http
- traefik.http.services.api_endpoint.loadbalancer.server.port=80
- traefik.http.routers.api_endpoint.rule=Host(`example.com`) && PathPrefix(`/api-endpoint`)
- traefik.http.middlewares.forward_auth_api_endpoint.forwardauth.address=http://rate_limiting:8080
- traefik.http.routers.api_endpoint.middlewares=forward_auth_api_endpoint
rate_limiting:
image: path_to_your_rate_limiting_image
deploy:
labels:
- traefik.http.routers.rate_limiting.entrypoints=http
- traefik.http.services.rate_limiting.loadbalancer.server.port=8080
Ahora tenemos una configuración completa de Docker Swarm + Traefik que primero reenvía las solicitudes a un servicio de limitación de velocidad antes de enrutar finalmente la solicitud al punto final de la API. Puedes poner lo anterior en un archivo production.yml e iniciar la aplicación con el siguiente comando:
docker stack deploy --with-registry-auth -c production.yml application_name
Tenga en cuenta que sólo se reenvían las cabeceras de las peticiones, no el contenido de las mismas. Esto es por razones de rendimiento. Así que si quieres autenticar una solicitud basándote en el cuerpo de la misma, tendrás que idear otra estrategia.
Gestión de la limitación de la velocidad con Go y el almacenamiento en caché
Las configuraciones de Traefik y Docker están listas. Ahora tenemos que codificar el microservicio Go que se encargará de limitar la velocidad de las peticiones: los usuarios sólo tienen derecho a 10 peticiones por minuto. Por encima de 10 peticiones por minuto, cada petición será rechazada con un código HTTP 429.
package main
import (
"fmt"
"time"
"log"
"net/http"
"github.com/gorilla/mux"
"github.com/patrickmn/go-cache"
)
var c *cache.Cache
// updateUsage increments the API calls in local cache.
func updateUsage(token) {
// We first try to increment the counter for this user.
// If there is no existing counter, an error is returned, and in that
// case we create a new counter with a 3 minute expiry (we don't want
// old counters to stay in memory forever).
_, err := c.IncrementInt(fmt.Sprintf("%v/%v", token, time.Now().Minute()), 1)
if err != nil {
c.Set(fmt.Sprintf("%v/%v", token, time.Now().Minute()), 1, 3*time.Minute)
}
}
func RateLimitingHandler(w http.ResponseWriter, r *http.Request) {
// Retrieve user API token from request headers.
// Not implemented here for the sake of simplicity.
apiToken := retrieveAPIToken(r)
var count int
if x, found := c.Get(fmt.Sprintf("%v/%v", apiToken, time.Now().Minute())); found {
count = x.(int)
}
if count >= 10 {
w.WriteHeader(http.StatusTooManyRequests)
return
}
updateUsage(apiToken)
w.WriteHeader(http.StatusOK)
}
func main() {
r := mux.NewRouter()
r.HandleFunc("/", RateLimitingHandler)
log.Println("API is ready and listening on 8080.")
log.Fatal(http.ListenAndServe(":8080", r))
}
Como puedes ver, estamos usando el toolkit Gorilla para crear una pequeña API, escuchando en el puerto 8080, que recibirá la petición enviada por Traefik.
Una vez recibida la petición, extraemos el token de usuario de la API de la petición (no se implementa aquí por simplicidad), y comprobamos el número de peticiones realizadas por el usuario asociado a este token de la API durante el último minuto.
El contador de peticiones se almacena en memoria gracias a la librería go-cache. Go-cache es una librería de caché minimalista para Go que es muy similar a Redis. Maneja automáticamente cosas importantes como la expiración de la caché. Almacenar los contadores de la API en memoria es crucial ya que es la solución más rápida, y queremos que este código sea lo más rápido posible para no ralentizar demasiado las peticiones de la API.
Si el usuario ha realizado más de 10 peticiones durante el minuto actual, la petición es rechazada con un código de error HTTP 429. Traefik verá que este error 429 no es un código 2XX, por lo que no permitirá que la solicitud del usuario llegue al punto final de la API, y propagará el error 429 al usuario.
Si la solicitud no está limitada por la tasa, automáticamente incrementamos el contador para este usuario.
Te recomiendo que despliegues esta aplicación Go dentro de un simple contenedor “scratch” (FROM scratch): es la forma más ligera de desplegar binarios Go con Docker.
Conclusión
Como puedes ver, implementar una pasarela de limitación de velocidad para tu API no es tan difícil, gracias a Traefik, Docker y Go.
Por supuesto, la limitación de la tasa basada en un número de solicitudes por minuto es sólo un primer paso. Puede que quieras hacer cosas más avanzadas como:
- Limitar la tasa por minuto, por hora, por día y por mes.
- Limitar la tasa por punto final de la API
- Tener un límite de tarifa variable por usuario dependiendo del plan al que esté suscrito
- Comprobar la concurrencia
¡Hay tantas cosas interesantes que no podemos mencionar en este artículo!
Si tiene preguntas, no dude en ponerse en contacto conmigo.





{kind=link}