

Limiting API usage based on advanced rate limiting rule is not so easy. In order to achieve this behind the NLP Cloud API, we’re using a combination of Traefik (as a reverse proxy) and local caching within a Go script. When done correctly, you can considerably improve the performance of your rate limiting and properly throttle API requests without sacrificing speed of the requests.
In this example we’re showing how to delegate the rate limiting of every API request to a dedicated microservice thanks to Traefik and Docker. Then in this dedicated microservice, we will count the number of requests recently made in order to authorize or not the new request.
Traefik As A Reverse Proxy
In order to set up an API gateway, Traefik and Docker are a very good combination.
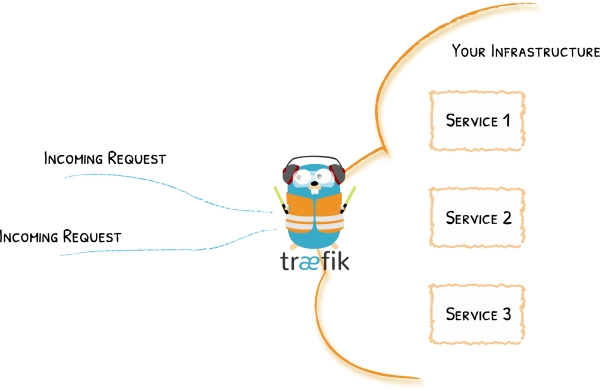
The idea is that all your API requests should be first routed to a Docker container containing a Traefik instance. This Traefik instance acts as a reverse proxy so it will do things like authentication, filtering, retrying, … and eventually routing the user request to the right container.
For example, if you are making a text summarization request on NLP Cloud, you will first go through the API gateway that will take care of authenticating your request and, if successfully authenticated, your request will be routed to a text summarization machine learning model contained in a dedicated Docker container hosted on a specific server.
Both Traefik and Docker are easy to use, and they make your program quite easy to maintain.
Why Use Go?
A rate limiting script will necessarily have to handle a huge volume of concurrent requests.
Go is a good candidate for this type of application as it processes your requests very quickly, and without consuming too much CPU and RAM.
Traefik and Docker were both written in Go, which must not be a coincidence…
A naive implementation would be to use the database to store API usage, count past user requests, and rate limit requests based on that. It will quickly raise performance issues as making a DB request every single time you want to check a request will overwhelm the DB and create tons of unnecessary network accesses. The best solution is to manage that locally in memory. The flip side, of course, it that in-memory counters are not persistent: if you restart your rate limiting application, you will lose all your ongoing counters. It should not be a big deal in theory for a rate limiting application.
Delegating API Rate Limiting To a Dedicated Microservice Thanks To Traefik And Docker
Traefik has many interesting features. One of them is the ability to forward authentication to a dedicated service.
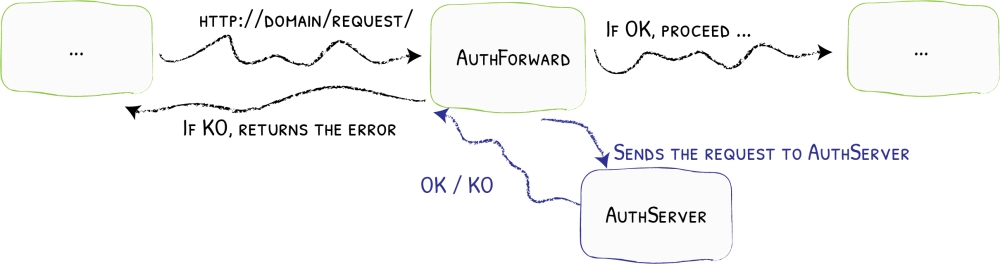
Basically, each incoming API request will first be forwarded to a dedicated service. If this service returns a code 2XX code, then the request is routed to the proper service, otherwise it is rejected.
In the following example, we will use a Docker Compose file for a Docker Swarm cluster. If you’re using another container orchestrator like Kubernetes, Traefik will work very well too.
First, create a Docker Compose file for your API endpoint and enable Traefik:
version: "3.8"
services:
traefik:
image: "traefik"
command:
- --providers.docker.swarmmode
api_endpoint:
image: path_to_api_endpoint_image
deploy:
labels:
- traefik.http.routers.api_endpoint.entrypoints=http
- traefik.http.services.api_endpoint.loadbalancer.server.port=80
- traefik.http.routers.api_endpoint.rule=Host(`example.com`) && PathPrefix(`/api-endpoint`)
Then add a new service dedicated to rate limiting and ask Traefik to forward all requests to it (we will code this Go rate limiting service a bit later):
version: "3.8"
services:
traefik:
image: traefik
command:
- --providers.docker.swarmmode
api_endpoint:
image: path_to_your_api_endpoint_image
deploy:
labels:
- traefik.http.routers.api_endpoint.entrypoints=http
- traefik.http.services.api_endpoint.loadbalancer.server.port=80
- traefik.http.routers.api_endpoint.rule=Host(`example.com`) && PathPrefix(`/api-endpoint`)
- traefik.http.middlewares.forward_auth_api_endpoint.forwardauth.address=http://rate_limiting:8080
- traefik.http.routers.api_endpoint.middlewares=forward_auth_api_endpoint
rate_limiting:
image: path_to_your_rate_limiting_image
deploy:
labels:
- traefik.http.routers.rate_limiting.entrypoints=http
- traefik.http.services.rate_limiting.loadbalancer.server.port=8080
We now have a full Docker Swarm + Traefik configuration that first forwards requests to a rate limiting service before eventually routing the request to the final API endpoint. You can put the above in a production.yml file and start the application with the following command:
docker stack deploy --with-registry-auth -c production.yml application_name
Note that only the headers of the requests are forwarded, not the content of the requests. This is for performance reasons. So if you want to authenticate a request based on the body of this request, you will need to come up with another strategy.
Handling Rate Limiting With Go And Caching
The Traefik and Docker configurations are ready. We now need to code the Go microservice that will take care of rate limiting the requests: users only have the right to 10 requests per minute. Above 10 requests per minute, every request will be rejected with a 429 HTTP code.
package main
import (
"fmt"
"time"
"log"
"net/http"
"github.com/gorilla/mux"
"github.com/patrickmn/go-cache"
)
var c *cache.Cache
// updateUsage increments the API calls in local cache.
func updateUsage(token) {
// We first try to increment the counter for this user.
// If there is no existing counter, an error is returned, and in that
// case we create a new counter with a 3 minute expiry (we don't want
// old counters to stay in memory forever).
_, err := c.IncrementInt(fmt.Sprintf("%v/%v", token, time.Now().Minute()), 1)
if err != nil {
c.Set(fmt.Sprintf("%v/%v", token, time.Now().Minute()), 1, 3*time.Minute)
}
}
func RateLimitingHandler(w http.ResponseWriter, r *http.Request) {
// Retrieve user API token from request headers.
// Not implemented here for the sake of simplicity.
apiToken := retrieveAPIToken(r)
var count int
if x, found := c.Get(fmt.Sprintf("%v/%v", apiToken, time.Now().Minute())); found {
count = x.(int)
}
if count >= 10 {
w.WriteHeader(http.StatusTooManyRequests)
return
}
updateUsage(apiToken)
w.WriteHeader(http.StatusOK)
}
func main() {
r := mux.NewRouter()
r.HandleFunc("/", RateLimitingHandler)
log.Println("API is ready and listening on 8080.")
log.Fatal(http.ListenAndServe(":8080", r))
}
As you can see, we’re using the Gorilla toolkit in order to create a small API, listening on port 8080, that will receive the request forwarded by Traefik.
Once the request is received, we extract the user API token from the request (not implemented here for the sake of simplicity), and check the number of requests made by the user associated with this API token during the last minute.
The request counter is stored in memory thanks to the go-cache library. Go-cache is a minimalist caching library for Go that is very similar to Redis. It automatically handles important things like cache expiry. Storing the API counters in memory is crucial as it is the fastest solution, and we want this code to be as fast as possible in order not to slow down API requests too much.
If the user has made more than 10 requests during the current minute, the request is rejected with a 429 HTTP error code. Traefik will see that this 429 error is not a 2XX code, so it won’t allow the user request to reach the API endpoint, and it will propagate the 429 error to the user.
If the request is not rate limited, we automatically increment the counter for this user.
I recommend that you deploy this Go application within a simple “scratch” container (FROM scratch): it is the lightest way to deploy Go binaries with Docker.
Conclusion
As you can see, implementing a rate limiting gateway for your API is not that hard, thanks to Traefik, Docker and Go.
Of course, rate limiting based on a number of requests per minute is only a first step. You might want to do more advanced things like:
- Rate limiting per minute, per hour, per day, and per month
- Rate limiting per API endpoint
- Have a variable rate limit per user depending on the plan he subscribed to
- Check concurrency
So many interesting things we can’t mention in this article!
If you have questions please don’t hesitate to reach out to me.





{kind=link}